Sarah’s Inbox: The Agony and the .tgz
Many of you have probably already seen that earlier today we stood up a copy of the Elena’s Inbox code for the Sarah Palin email collection. You can find the site here. I think that by most reasonable standards, Sarah Palin is currently a less newsworthy figure than Justice Kagan was at the time of her confirmation. But there’s no question that many people find her fascinating, and folks seem to really enjoy having this sort of interface available — the response has been overwhelmingly positive, even in spite of its horrifying Gmail 1.0 look (for what it’s worth, Sunlight’s design team deserves absolutely none of the blame for this one!).
It’s worth taking a moment to reflect on what it took to get this site online. The state of Alaska released Governor Palin’s email records on paper. News organizations had to have people on the ground to collect, scan and OCR these documents. Our thanks goes out to Crivella West, msnbc.com, Mother Jones and Pro Publica, whose incredibly quick and high-quality work provided us with the baseline data that powers the site.
But it wasn’t yet structured data. It was easy enough to convert the PDFs into text, though this introduced some errors — dates from the year “20Q7”, for instance. Then we had to parse the text into documents, each with recipients, a subject line, and a sender. This is trickier than it might seem. Consider the following recipient list:
To: Smith, John; Jane Doe; Anderson; Andy (GOV); Paul Paulson
It’s parseable… sort of. It turns out that, in this case, “Andy Anderson” should be treated as an entity. In this dataset, portions of names are delimited by semicolons, but so are names. It’s a bit of a mess. Sunlight staff spent the better part of Monday performing a manual merge of the detected entities, collapsing over 6,000 automatically-captured people to less than half that number. I won’t pretend that the dataset is now spotless, but it’s considerably more structured than it used to be.
And that structure makes possible not only novel interfaces like Sarah’s Inbox, but also novel analyses. Consider this graph of how often the word “McCain” appears in the emails:
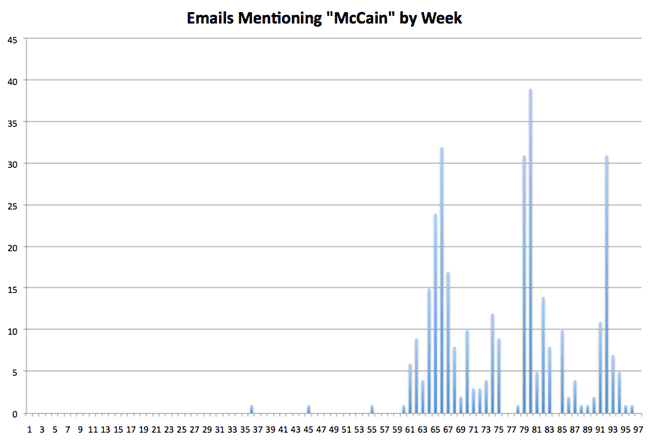
Interesting, right? More substantively, consider the efforts of Andree McCloud, who’s raising questions about an apparent gap in the Palin emails near the beginning of the governor’s term. With the data captured, it’s easy to visualize this — here’s a graph of the total email volume in the system by week, beginning with the first week of December 2006, when Palin took office:
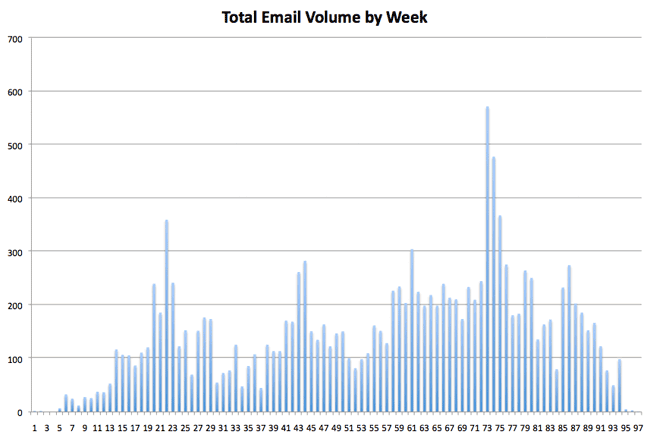
(To be clear, I don’t think you can necessarily conclude from this graph that there’s anything nefarious about that period’s low email volume — there are plenty of potential explanations. Still, it’s useful to be able to be able to understand the outlier period in the larger context of the document corpus.)
Of course, these analyses and interfaces could be even better if Alaska had just released the files digitally. In fact, if they had, we might be able to draw some more solid conclusions: as our sysadmin Tim pointed out, message headers’ often-sequential IDs could conceivably show whether there actually are missing emails from those first few weeks.
It’s a shame that that didn’t happen — and not just because it meant my weekend was spent parsing PDFs. Releasing properly structured data ultimately allows everyone to do better work in less time. It’s unfortunate that the authorities in Alaska introduced such a substantial and unnecessary roadblock.
But we at Sunlight can at least share what we’ve done to improve the situation. If you’re interested in running your own analysis, you can find our code here, and the data to power it here (12M). At the moment it’s in the form of a Django project — if you need it in a different format, don’t hesitate to ask on our mailing list. If you do something neat with it, please tell us!