OpenGov Voices: Local Government Financial Transparency: Scaling It Up

Disclaimer: The opinions expressed by the guest blogger and those providing comments are theirs alone and do not reflect the opinions of the Sunlight Foundation or any employee thereof. Sunlight Foundation is not responsible for the accuracy of any of the information within the guest blog.
Marc Joffe is the founder of Public Sector Credit Solutions (PSCS) which applies open data and analytics to rating government bonds. Before starting PSCS, Marc was a Senior Director at Moody’s Analytics. You can contact him at marc@publicsectorcredit.org.
Groups like OpenOakland and Open City have done some great work in making local government financial data more accessible. Machine readable data sets and visualizations help citizens better understand how their tax money is being used.
Because these efforts typically require volunteers and/or visionary political leaders, they tend to focus on individual governmental units. Since the U.S. has some 80,000 local governments, it is unlikely that these standalone projects will give us anything like nationwide transparency of local government fiscal data. Building a nationwide open data set would be very beneficial because it would allow users to compare their city or county to comparable units across the country. It could answer such questions as “how does our public safety spending stack up against other cities with similar population and crime rate?” It could also allow us to compare the fiscal condition of cities in order to see which are headed in the direction of Detroit, Harrisburg, San Bernardino and Stockton – toward bankruptcy.
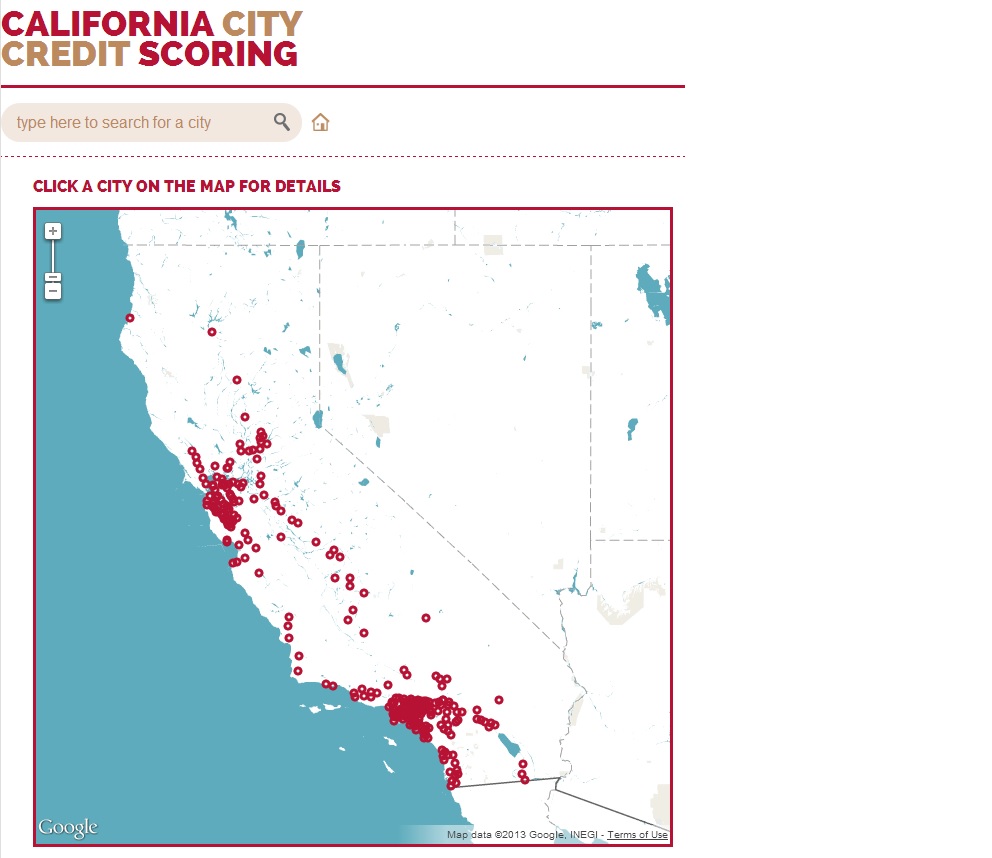 A Mountain View California based company, OpenGov.com, is working with several local governments to place their fiscal data online, in graphical form. If successful, this firm could greatly increase the amount of open government financial data – for those governments that are willing to subscribe to their transparency service.
A Mountain View California based company, OpenGov.com, is working with several local governments to place their fiscal data online, in graphical form. If successful, this firm could greatly increase the amount of open government financial data – for those governments that are willing to subscribe to their transparency service.
But what about situations in which a local government is unwilling to cooperate and volunteers are unavailable? This universe is likely to include some of the more fiscally irresponsible governments in places that lack tech-savvy, engaged citizens.
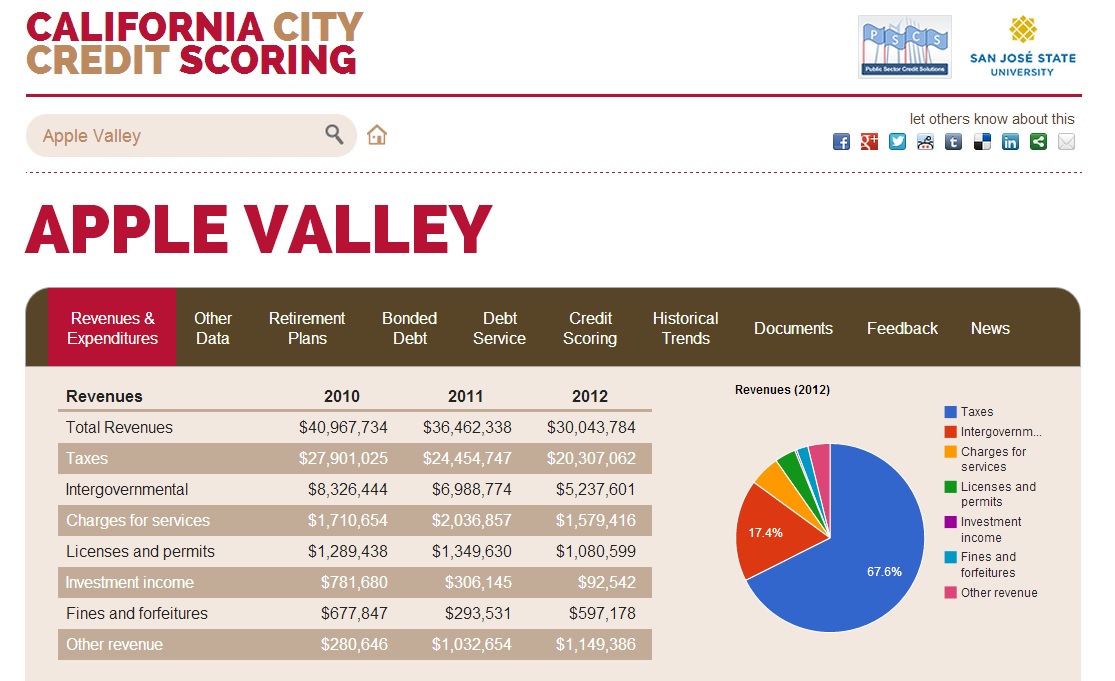
In these cases, we can collect and report data on behalf of those governments. Recently, my group, Public Sector Credit Solutions, collected legally mandated financial reports from 260 city governments in California. We extracted standardized data from these reports and placed the information online for free here. We’d love to work with other groups to roll out this type of fiscal transparency to other types of local governments (like counties and regional transportation districts) and to the rest of the country.
Collecting Local Government Fiscal Data
Local governments are typically required to produce two types of financial reports: (1) audited financial statements and (2) budgets. We worked primarily with the former type of document. The rest of this post discusses how to make these reports transparent on a large scale.
The first challenge is one of locating the documents. There is no nationwide repository of budgets, but there are some resources that store significant numbers of audited financials. The largest such resource is the Municipal Securities Rulemaking Board’s EMMA system. (EMMA stands for Electronic Municipal Market Access). Any local government issuing municipal bonds is required to upload their audited financial statements to EMMA. Many governments don’t issue bonds and some that do fail to comply with this mandate, so EMMA’s collection is far from complete. Also, because the system is organized around municipal bond issues, it is not easy to find all the financial reports it contains. We achieved much better results by navigating to each city’s website and downloading its reports. Since EMMA does not collect budgets, any effort that includes forward-looking data will require visiting individual local government websites, anyway. (Note: as I learned from the folks at 360-Public, a number of states have repositories for audited financials.)
Local governments vary regarding where on their sites they post financial PDFs. They also vary as to what extent they store documents from previous years. For anyone wishing to build a history of financial documents, I suggest downloading and storing them on your own hardware, because these documents could suddenly disappear from the local government’s site. In some cases, the Internet Archive’s Wayback Machine can be used to retrieve older documents. Otherwise, it may be necessary to call the city or county and ask for documents. Calling may even be necessary for current documents since some local governments do not automatically post them. We found that city government finance and administrative employees were generally very responsive to our requests for files. We only had to invoke California’s public records law once, and that was for the purpose of collecting 15-year old audited financials so that we could perform forensic accounting on a city that had previously declared bankrupt.
In the vast majority of cases, the financial reports are published as PDFs. Adobe did the world a great favor by creating a universal document format, but the PDF poses serious challenges to the open data community: unlike data stored in spreadsheets and text files, data embedded in PDFs is difficult to extract and use (Read what Sunlight has said in the past about why we must go beyond publishing in PDFs).
Software is available to extract data from PDFs, but the process is highly manual. PDFs containing financial data are typically generated either by “printing” from an application to a PDF or by scanning paper documents. In the former case, the data remains embedded in the PDF. Desktop software products like Able2Extract and NitroPDF can readily extract this embedded data and save it to a spreadsheet. We get the best results by manually selecting portions of the PDF to convert within the software, and we often have to “massage” the extracted spreadsheet after conversion.
Scanned PDFs are even more of a headache because Optical Character Recognition (OCR) technology must be applied to these documents before any data can be harvested. We often get pretty good results with Abbyy FineReader. Able2Extract and NitroPDF both have optional OCR modules, but we do not have experience with those added cost features.
To properly automate the data collection process, we need tools that can intelligently analyze and extract selected, structured data from PDFs. Although such tools are available in the world of enterprise software (at very high price points), we have not seen any open source tools that satisfactorily address this important application – an application that is relevant to many types of open government projects; not just those involving financial data.
For now, projects like ours require a lot of human effort. We minimize these costs by using an offshore outsourcing firm that has developed expertise in the areas of gathering and analyzing local government financial disclosures. Other alternatives we’ve explored involve the use of crowdsourcing work platforms such as Amazon Mechanical Turk and Crowdflower, or individual freelancers accessible on sites such as eLance.
Gathering and making transparent the entire universe of local government data is a challenging endeavor. Please reply to this post if you have other ideas about how to approach this problem (I will be discussing this topic at OkCon and want to highlight as many applicable technologies as I can) or if you would like to collaborate on this project.
Interested in writing a guest blog for Sunlight? Email us at guestblog@sunlightfoundation.com.