OpenGov Voices: PySEC, bringing corporate financial data to the masses
Disclaimer: The opinions expressed by the guest blogger and those providing comments are theirs alone and do not reflect the opinions of the Sunlight Foundation or any employee thereof. Sunlight Foundation is not responsible for the accuracy of any of the information within the guest blog.
do not reflect the opinions of the Sunlight Foundation or any employee thereof. Sunlight Foundation is not responsible for the accuracy of any of the information within the guest blog.
Luke Rosiak is a former Sunlight Foundation reporter and database analyst who now writes for the Washington Examiner. This post addresses the tooling around Extensible Business Reporting Language and provides recommendations on what needs to be done. You can reach Luke on Twitter at @lukerosiak.
In the early 1990s, long before most federal agencies had embraced the digital era, the Securities and Exchange Commission (SEC) undertook a truly “big data” initiative that showcased some of the best that open data had to offer: Its quarterly reports were uploaded in real time, in text, rather than PDF, format, to a public FTP server called EDGAR. (File Transfer Protocol or FTP is a standard network protocol used to copy a file from one host to another over a network.)
Like with the Federal Election Commission, the companies submitted their own reports, but they immediately entered the public record, and it was the government who required the submissions, dictated the forms and made them available.
EDGAR, which was implemented in part by Sunlight Foundation supporter Carl Malamud, revolutionized a massive industry of financial watchers who used the reports to decide what companies to invest in–and which to dump. Firms like Bloomberg and Reuters processed the text files into structured data, and analysts pored over them.
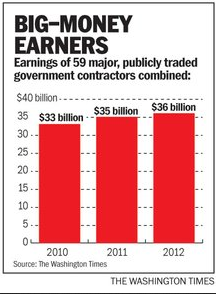 And before long, the SEC was pushing the ball even further, with talk of XBRL or Extensible Business Reporting Language. After all, financial information was almost entirely numbers-based, lending itself to computer analysis, and was fairly structured, with accountants all using a core of the same carefully-defined terms–though Wall Street accounting is too complex to fit in simple columns and rows, necessitating nested structures and the ability to dynamically define new terms.
And before long, the SEC was pushing the ball even further, with talk of XBRL or Extensible Business Reporting Language. After all, financial information was almost entirely numbers-based, lending itself to computer analysis, and was fairly structured, with accountants all using a core of the same carefully-defined terms–though Wall Street accounting is too complex to fit in simple columns and rows, necessitating nested structures and the ability to dynamically define new terms.
The X in XBRL was a double-edged sword there. XBRL’s power, advocates said, was derived from its flexibility. It was a unified language that could express financial ideas whether the company was trading goats in Ethiopia or derivatives in Manhattan. To provide that kind of flexibility, it allowed accountants to define their own terms in financial documents, extending from a base of agreed-upon terms, in America called the US-GAAP.
But the US-GAAP itself had thousands of terms, and accountants who were accustomed to filing paper reports never bothered to learn its structure. Lazy filers created their own custom terms when buried somewhere in the GAAP, there was already a universal term that meant the same thing. That defeated the purpose of structured reporting, because it made comparing across companies impossible.
For years, those things caused the cycle to continue, even after the SEC mandated that all filers report using XBRL for all reports in 2009. There are indications that accuracy is no longer any kind of deal-breaker, yet there are still few usable open-source tools to process the reports.
That’s largely because government data is at its most powerful when users have a combination of both technical and domain knowledge. The smartest programmers in the world won’t know how to find meaningful insights in campaign contribution data if they don’t know the way Capitol Hill and campaign finance law work.
The robust community of open source developers and open government activists, meanwhile, is often pretty distinct from the money-driven world of Wall Street, and shied away from XBRL because they weren’t confident in their corporate finance prowess–an instinct that’s entirely understandable when you see the 200-character mumbo-jumbo of corporate-speak that XBRL terms describe, which could make anyone’s eyes glaze over.
When those two groups get together, though, that chasm can be bridged pretty quickly, and that’s what we’ve done with a Python library that deals with financial documents in a way that, I hope, is straightforward enough to bring structured financial data to the opengov masses.
And of course, while most of the industry analysts’ focus is on quarterly earnings, we’re talking about detailed information about every publicly traded company–companies that lobby, that pay fines, that caused the Wall Street collapse, and that create jobs. Companies that overpay their executives, companies that hide revenue in tax havens.
Here’s, for example, how profitable some defense contractors are, and a resulting article on their persistent profitability.
The SEC should be commended for being–for decades–on the forefront of open data, and the community can use it for accountability and for generally learning about, analyzing and visualizing information about our economy.
Below is a Python library I created in collaboration with accountants and developers:
PySEC is a Django application that makes the Securities and Exchange Commission’s index of filings of all different types–including narrative annual statements to shareholders, called proxies, and structured data representing annual and quarterly financials–easily accessible.
At its heart is a Python parser that deals with XBRL, the XML variant tailored to business reporting. An XBRL document is comprised of four separate files, which causes most people to turn and run, but it turns out that you can more or less ignore all but one of them.
The django management command sec_import_index compiles a list of all SEC filings from EDGAR into SQL, populating the Index model, and will lazily download them as you access them.
Calling the .xbrl() function on an Index model representing an annual report, called a 10-K, will initialize the XBRL parser such that you can pass it any XBRL tag, such as Revenues, and it will spit out the value–which is a lot harder than it looks because there are many “contexts,” representing a combination of time periods and corporate subsidiaries, for each tag. The parser handles all that behind the scenes.
And xbrl_fundamentals is where the magic happens, applying some obscure logic to populate a dictionary of 50+ key accounting terms, picking and choosing among several options to navigate accounting caveats and missing values. The result are reliable terms that can be understood by humans, not just accountants.
(The XBRL fundamentals parser is pretty much translated directly from a Visual Basic script written by Charles Hoffman, an accountant and XBRL expert, and he has achieved more than 95 percent accuracy for each accounting concept.)
To set up the index of all SEC filings:
Put this django app under manage.py and do your settings.py
In settings.py, modify DATA_DIR = ‘/you/directory/to/download/files/to’ and set your database
python manage.py syncdb
python manage.py sec_import_index
This creates the Index() model. To get its XBRL attributes if it’s a form=”10-K”, call .xbrl() on it and look at the .fields attribute of the returned model.
To get any additional XBRL term:
x.GetFactValue(XMBL TAG, “Duration” or “Instant” (depending on if it’s a year-long or snapshot value))
For more basic usage, see example.py
For an example of generating a CSV of a list of companies, see management/commands/xbrl_to_csv.py
Here’s a sample output of that command, and an example of the kind of information you can easily get.
Just the beginnings
This is just the scaffolding, but the possibilities from here are endless. The obvious and trivial next step is to set this up to fetch filings in real-time and save the 50+ common financial attributes to a relational database.
Embed sample data:
Or if you don’t want to commit to maintaining a real-time index of all SEC filings (I downloaded all the 2012 10-Ks and it was 100GB) it would be trivial to set it up as an API that took the URL of the filing on the SEC’s page and spit out a dict with the common terms.
(There are usually two previous years contained in a given year’s financials for historical comparisons, so the returned dict would probably have three keys representing years, each of which would have 50 keys representing terms.)
From there, answering questions like ‘which company paid the least in taxes’ or ‘how does company X’s profit margin compare with company Y’s’ are trivial.
The proxy statements (form=”DEF 14A” are narratives, but provide a great playground for experimentation in text analysis, and they are also filled with HTML tables representing arbitrary data that can easily be turned into CSVs (including executive compensation).
Its source is on GitHub here.
Would love to see some community involvement and to have patches and improvements merged in, and to see the results of what this is used for!
Interested in writing a guest blog for Sunlight? Email us at guestblog@sunlightfoundation.com.