OpenGov Voices: How Datasembly plans to make open data more discoverable and usable


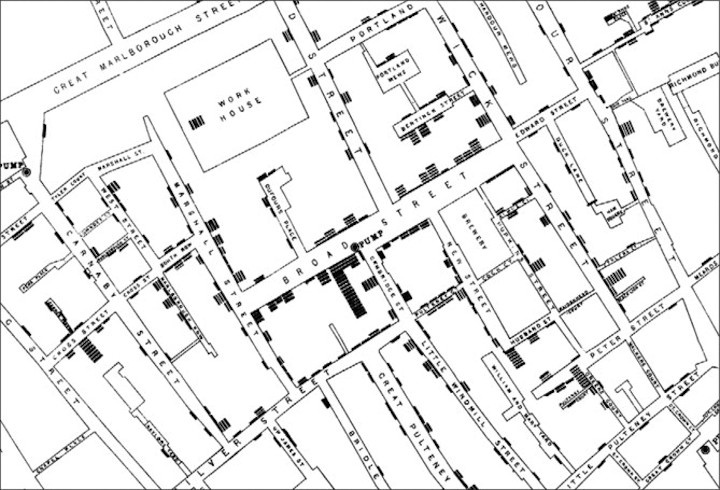
In 1854, Dr. John Snow traced the source of a cholera outbreak in London to a water pump by overlaying a map of cholera infections with a map of water wells. In doing so, he saved many from infection and revolutionized the study of communicable disease. Today, public health data and the location of city utilities is more and more likely to be among data that is openly and publicly available.
Over the last several years, the amount of available public data has increased at a seemingly exponential rate. Hundreds of governments around the world have released millions of data sets and continue to improve the quality of the data being released. Historic new rules like President Obama’s Open Data Policy underscore the promising future of open data. Of course, there is room for improvement — and there always will be — but the state of open data is better than it ever has been and the positive momentum is staggering.
The increase of the availability of open data should make it easier for analysts, like John Snow, to find patterns, solve problems and have better insight into the actions of the government, but simply providing data has not been a silver bullet. Many would-be open data users are now drowning in a veritable ocean of public data. These citizens are turning to the open-data universe to answer their questions, but too many of them are overwhelmed by the disparate sources and the sheer amount of data.
We founded Datasembly to make open data more discoverable and usable. Our goal is to empower technical and non-technical users to find answers in the universe of open data.
Datasembly organizes the contents of the the world’s open data by extracting real knowledge from the data. This enables us to build tools that make sense of the content of data sets from disparate sources.
We have started by extracting time and location data from data sets, since these critical factors answer the most basic questions about data: where and when did this occur? These factors are relevant for many data sets and extracting and indexing the answers enables Datasembly to comb through data sets efficiently.
Other data aggregators are focused on allowing users to search metadata (manually curated information about the data). Datasembly differs because it understands some core aspects of the data and can automatically extract critical information — like intersections in space and time.
Location is of special importance because, although it may initially seem like a simple piece of information, it can be rather complex to work with. We have heard from users that they struggle to work with data sets whose location information might be based on address, latitude/longitude, census tract, zip code, neighborhood, etc. Understanding how these different geographies fit together is nontrivial. The Datasembly platform intelligently extracts this information from data sets as they are indexed into our system, allowing downstream tools to circumvent this problem entirely.
Other data aggregators also allow users to discover relevant data sets only once they have a hypothesis that might explain their phenomena of interest, but we want to enable users to explore open data pre-theoretically. With Datasembly, a user can search through the universe of open data without a hypothesis and find correlations and explanations. This kind of exploration will allow users not only to use open data they know about, but discover new types of data that they may have not realized existed. Using open data for hypothesis generation will inevitably increase the exposure of the data and ultimately lead to increased knowledge discovery and transparency.
We are eager to hear about the problems that open-data users face. We are confident that the Datasembly platform, having indexed so much public data based on location and time, will enable us to build useful tools better and faster than was previously possible. Please do not hesitate to reach out with any ideas or comments.
We could not possibly get Datasembly off the ground without support from the Sunlight Foundation OpenGov Grant and we want to extend them a huge thank you.
Ben Reich and Dan Gallagher are founders of Datasembly.com located in Washington DC. Datasembly is an open-data platform that aggregates and indexes the world’s open data sources. You can reach them at ben@datasembly.com and dan@datasembly.com.
Interested in writing a guest blog for Sunlight? Email us at guestblog@sunlightfoundation.com