Converting HTML to PDF (uh oh): How we built #FOIApoetry
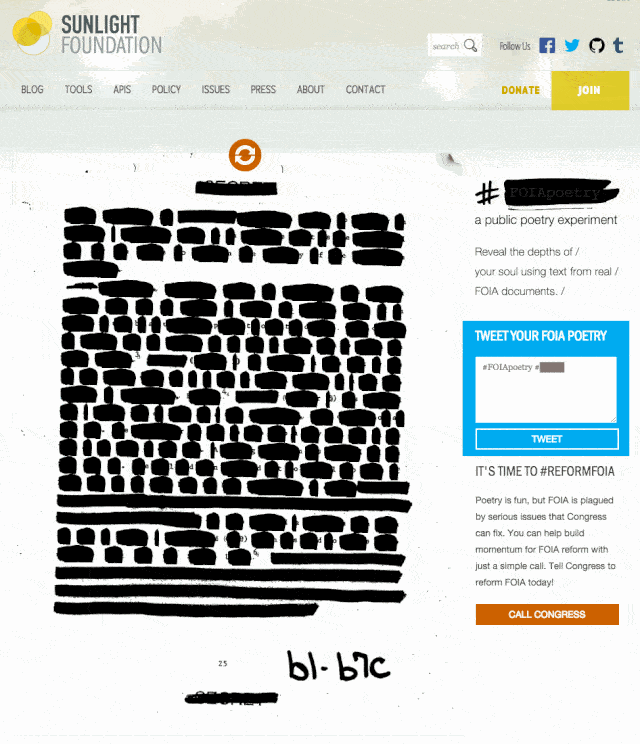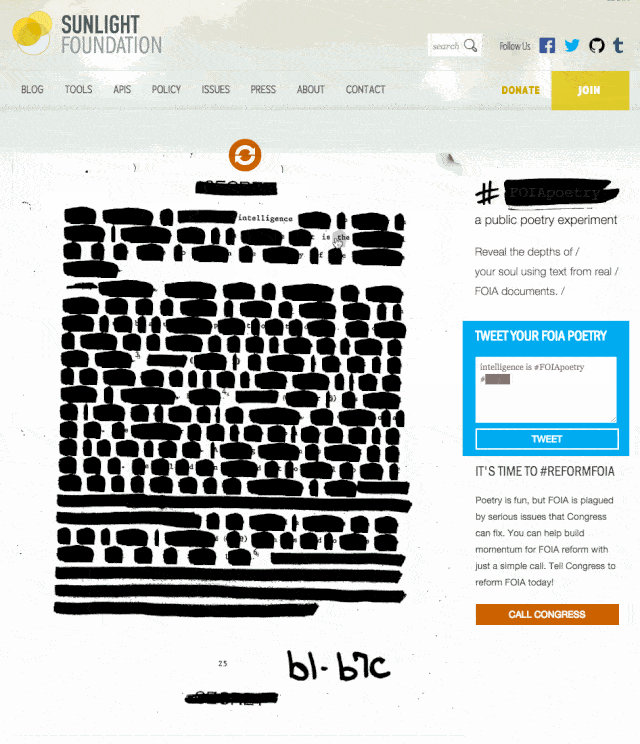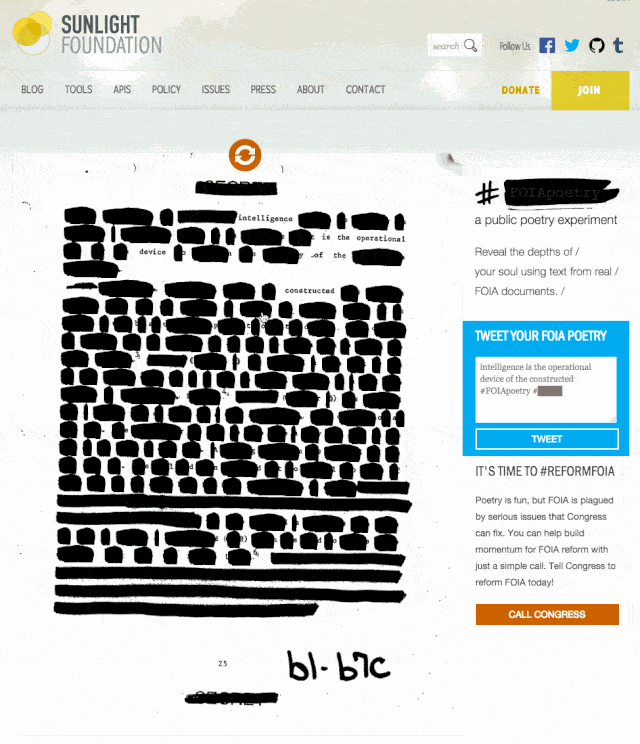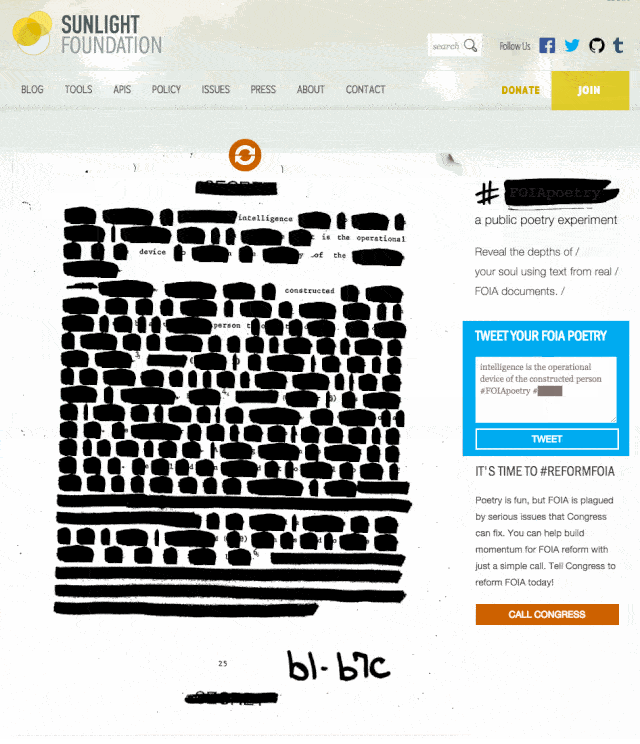
We just finished up and launched a small side project to encourage engagement around Sunshine Week and FOIA reform. #FOIApoetry invites users to explore and create by hovering over artificially redacted words on real FOIA documents. It was a fun, challenging experience, so we decided to write about how the tool came to be.
##Constraints Having fun with FOIA poetry, nonsensical documents and pages that have almost no content left on them seemed like a good idea, but just like working with FOIA documents for serious purposes, we quickly realized that repurposing comically redacted documents for play was going to be difficult. No content is no content whether you’re trying to make a political point or a poem.
With that in mind, we decided that artificially redacting real FOIA pages would prove to be much more feasible. It was important to us though, that we were asking the users to “unredact” words rather than have them apply more redactions to a document. Enter #FOIApoetry, inspired by the Newspaper Blackout project of author and artist Austin Kleon.
##How we did it To create a tool that could generate a tweet based on a PDF, we needed to have machine readable text. The PDFs we are using are old. Most of them were originally written in the ’70s and are uncomfortably legible to the human eye. They certainly aren’t naturally readable to a computer. We could have tried OCRing the PDFs we intended to use, but since we were constraining this project to three documents it was faster to just type them out by hand, including placeholders for every instance of a redaction or simply use an online merger.
As a designer, my goal was to preserve the experience of reading a badly designed, scanned PDF as much as I could (it’s an important part of interacting with FOIA documents!) while ensuring that the tool was still a technically pleasing experience. To do this, I layered the hand-typed HTML of the document on top of the original PDF and then did my best to align the type of the PDF and HTML.
I did this by first matching the font styles that were originally used. Thankfully, fonts available to most government employees in the mid-20th Century were limited to only a handful of basic fonts that are still available today.
Styling those fonts was a little trickier though. CSS is much more versatile today than it was even a few years ago, but it’s still much more limited than other tools I can work with for printed documents. For instance, in a program that is optimized for laying out type for print, minor adjustments of type size can be made at the decimal level of round units of measure, traditionally points. In CSS, we’re limited to whole pixels as our smallest unit of display, with a few other things we control, like -webkit-font-smoothing or -moz-osx-font-smoothing. We run into these same limits with rounded units in properties like line-spacing as well. This is all to say that as fun as it was to be able to find an exact match for the font-family used in the original documents, there were still some manual modifications that needed to be made to get things lined up.
For each of the documents, I used a variation of the CSS properties shown above. All of the documents required manual overrides with inline styles on some elements. For instance, in “Espionage in the Air force since World War II,” the author made the ill-advised choice to use two spaces between each sentence. (Perhaps they could be pardoned for this type misdemeanor given that their typewriter training may have happened before sentence spacing conventions began changing in the middle of last century.) This spacing choice did not match up with standard browser interpretations of post-period spaces. And, in fact, its double spaces could not be reconciled by adding an additional space, even by forcing extra space using ;. Instead, I used margin-left on the first word of each sentence to force the additional space.
I also combated slight differences in line-spacing interpretation by forcing additional space between paragraphs to reset the alignment as often as I could. Just the slightest difference in line-spacing multiplied across several lines created wildly inaccurate results without that hack.
The simplest, but most important use of CSS on each of these documents was the transform property, which allowed me to rotate the HTML text to align it with the slightly askew nature of the scanned documents.
Aside from all of the manual adjustments necessary to get the type aligned correctly, the other effort I made to make this piece feel like a more authentic document was in creating a redaction mark that felt a bit more human than a simple black background color on a div.
First, we wrapped each word in the layered HTML with a <span>
and set the value of color: to an RGBA with an alpha value of 0. Using alpha on the type instead of setting the opacity to 0 allowed me to continue controlling other visible elements of each span. To get the effect of the redaction, I used an SVG created to look like a marker stroke and applied that to the background of each <span>. The natural behavior of an SVG when applied to a background element is to display it’s full size, with overflow hidden beyond the size of the container object. Constraining the max size of the SVG to the dimensions of the containing object is moderately easy using background-size: contain;, but it naturally constrains the proportions as well which resulted in a nearly invisible SVG on single character words.
{kind=link}
{kind=link}
preserveAspectRatio="none"This problem was resolved by modifying a property in the SVG file itself. By adding preserveAspectRatio="none" to the raw SVG code, it allows the image to stretch to 100 percent width and 100 percent height. This resulted in enough variation in shape, while continuing to cover each of the words fully.
This process was very manual and not one that could be repeated at scale, but the challenge of trying to accurately replicate the nuances of print in the more confined language of CSS was a nice challenge.
We hope you enjoyed #FOIApoetry; if you haven’t tried it out, you can create your own ode to openness here.