Downgrading the district: Why we’re lowering D.C.’s legislative data score

“All the awful design of the 1995 Geocities website you knew with none of the old site’s functionality.” That’s how Alabama-based journalist Kyle Whitmire [describes the Yellowhammer State’s new legislative website](http://www.al.com/opinion/index.ssf/2015/02/youve_got_fail_alabama_legisla.html).
It’s true: Alabama’s website is easy to pick on. In addition to the site’s heavy reliance on fake marble texture, it’s nearly impossible for anyone, human or machine, to find anything. It took the Open States team two weeks of developer time to get our hands on Alabama’s legislative information. In more typical cases, we can adapt to a new website in about a day.
It doesn’t take a terrible front-end to get in the way of data availability, however. Another jurisdiction that has taken up a disproportionate amount of Team Open States’ time is Washington, D.C. The district also has a [new legislative website](http://lims.dccouncil.us/), and it’s slick! Navigating by hand, it’s quite easy to find legislators and legislation. There’s even an export function that provides this information as an Excel document or PDF. And they should be commended for that. But there’s a lot missing from the export — no information about amending a bill, committee action or how legislators voted, which all play an important part in tracking what a legislature is doing. With the district’s new site, there’s no way to get ahold of that information in bulk. Usually, that’s not a problem for our web-scraping skills. The back-end of D.C.’s legislative site, however, is nearly impossible to navigate. Here are a few lessons from D.C.’s new interface for anyone publishing public data to consider.
- If you’re going to load JSON into HTML templates, make a public API! The district’s site loads all data through so-called JSON -fetched via AJAX calls (more on their JSON in a minute), but this raw data isn’t easily available. It took significant searching along with careful header and parameter passing to find it. Credit to V. David Zvenyach who figured the headers out first and put a sample on Github — you saved us a lot of work!
- If you’re going to use JSON, make it properly formatted. D.C.’s JSON seems to have been recursively string-encoded — every field was turned into a string independently. Here’s a small portion of B21-0023, the Marijuana Legalization and Regularization act of 2015, exactly as taken from the district’s legislative website:
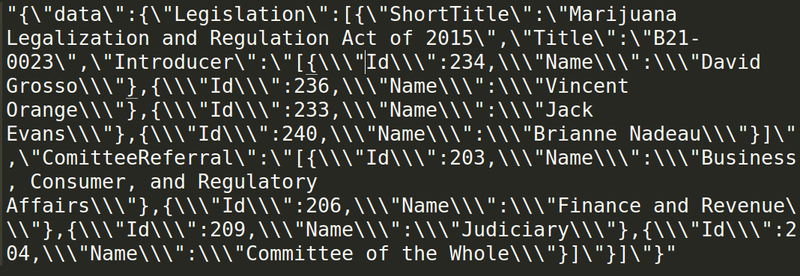
JSON, stringified Look at all those escaped strings! The data we need are in here, but since each sub-JSON object is encoded as a string, it can’t be decoded easily. We ended up writing a recursive JSON-decoding function to handle these data; check it out in the D.C. Bills scraper on Github.
- Provide documentation. Without any kind of explanation about the meaning and content of JSON headers, we are stuck making educated guesses. For example, the data related to mayoral review of legislation includes the following fields populated with dates: “TransmittedDate,” “SignedDate,” “EnactedDate,” “ResponseDate,” “ReturnedDate,” “ActExpirationDate,” and “Modified.” While some of these dates are more clear from the field name than others, we were not able to be fully confident of exactly what we were recording.
- Check spelling. While it seems nitpicky, spelling words incorrectly can have serious consequences for matching and combining data. A few examples:
- D.C. spells “committee” three different ways — “Comittee,” “Comitee” and “Committee” — in JSON field names, making it hard to know when to use which when searching for data.
- Amusingly, D.C. misspells JSON. In the part of the data referring to votes, they use the header “MappedJASON” to indicate councilmembers’ votes.
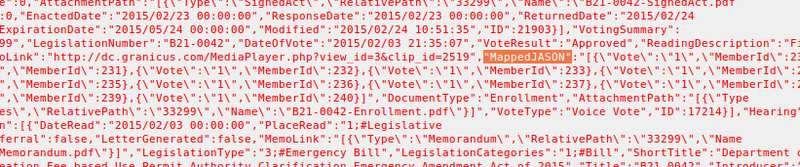
JASON - Council Chair Phil Mendelson is referred to as “Phil Pmendelson” in the JSON data on bills he sponsored.
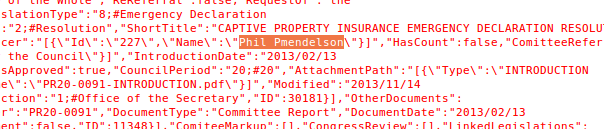
Council chair is apparently “Phil Pmendelson”
While we commend D.C. on the fact that it’s made an effort to release bulk data, its near-complete reliance on Javascript and poorly-formed JSON forces us to update the entry in the Open Legislative Data Report Card. Washington, D.C. previously got a C, which is pretty much average for the states, but we’re now forced to mark it down to a D. We’ve changed the scores in the following categories:
- Ease of Access: While the site is easy enough to navigate by a person with good vision using a modern browser, the complete reliance on Javascript makes it extremely difficult for people with older technology or individuals relying on assistive devices to use the site. We thus downgrade D.C. from a 0 to a -1: “Site was considered more difficult than average to use by members of staff or volunteers or had more severe Javascript dependencies.”
- Machine Readability: This category was somewhat harder to quantify. D.C. provided a significant amount of data in bulk, machine-readable forms (specifically Excel data dumps), but the data that could not be accessed in this way were only available by emulating Javascript. We thus downgrade D.C. from 0 to -1: “Site was considered more difficult than average to use by members of staff or volunteers or had more severe Javascript dependencies.”
- Timeliness: On the other hand, we were able to confirm with the Council secretary’s office that data is uploaded “as soon as it arrives and is reviewed.” We thus upgrade D.C. from 0 to 1: “Multiple updates throughout the day, in real time or as close to it as systems will allow.”
- The categories of Completeness, Standards and Permanence remained unchanged.
These changes taken together move D.C.’s score from a C to a D.