Making JSON as simple as a spreadsheet
JSON code
CSV and JSON are two of the most common kinds of files for open data you’ll find on the web today. CSVs are just spreadsheets and are a common way to let people download data in bulk. Tables of data are simple, and a great many people are used to working with them in Excel or Google Docs.
JSON has become the format of choice for APIs on the web today, but JSON data is trickier to work with for many people. Partly, this is because tables are just simpler for people to understand, and JSON data is rarely organized like a table. But maybe more importantly, there are great visual tools for working with CSVs, and few such tools for JSON.
In other words, if you send someone a link to a CSV, their browser downloads a file for them and they open it in Excel. If you send someone a link to JSON, their browser displays them a bunch of gobbledygook.
No good: This gives JSON a bad name.
Making JSON more approachable
A few weeks ago, I gave a workshop at Open Data Day here in D.C., the goal of which was to demystify JSON and make it feel as approachable as a spreadsheet.
I searched, but couldn’t find any good tools to do this that worked inside the browser. The only solution was to make a new one!
So now, if you go to konklone.io/json, you’ll see a box to paste JSON into:
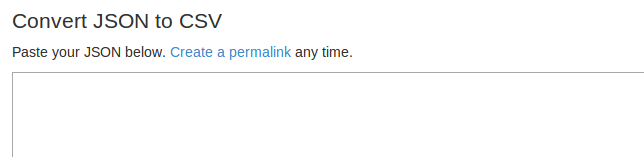
It’ll then quickly reformat and re-color your JSON…

…and transform it into a table of data below, showing you the first few rows.
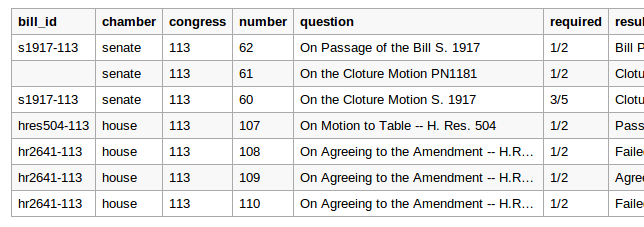
You can then click a link above the excerpt to download the full table as a CSV. At any time, you can click “Create a permalink” to save the data and change the URL to a unique link. Anyone visiting this permalink will see that same highlighted JSON and table.

For example, this URL shows recent new US laws from our Congress API, and this URL shows the official data catalog of the Treasury and IRS.
And that’s all you need to know to use it. If you’re interested in the technical underpinnings, read on.
How it works
The whole thing is mostly just other people’s work glued together.
When you paste in JSON, the converter parses it and then guesses at what the “rows” are by rifling through the JSON for an array. Each row is recursively flattened using an adapted algorithm from csvkit], a terrific command line tool by Chris Grozkopf et al for messing with CSV (and the inspiration for this project).
Flattened rows are fed into jquery-csv at Ben Balter’s suggestion, and that produces the raw CSV string. The converter then makes a ‘data:’ URI out of the CSV, and updates the download link. The download link takes advantage of a relatively recent feature in HTML5, the ‘download’ attribute for ” tags, to tell the browser to download the linked content rather than display it.
The JSON also gets run through highlight.js to produce a nicely formatted, more readable version. The CSV gets rendered into a table using some simple JavaScript and CSS, modeled after Github’s[own CSV rendering.
All of this makes it possible to run the whole converter **without a server**, inside the browser, as a static site.
Github as infrastructure
Github’s public services make this easy.
The website is hosted for free, via Github Pages. To make permalinks work, the converter stores raw JSON in an anonymous Gist using the Github API. (There’s a rate limit of 60 anonymous API requests per-hour per-visitor, but in practice that’s been fine.)
And of course, Github is where you can find the code, which is dedicated to the public domain.
It’s not perfect — it can’t handle every possible JSON structure you can throw at it, it could be better at telling you about errors and there are surely other bugs. Please describe any issues or suggestions on the issue tracker, which is once again over on Github.
It’s not so bad
If you want to get more comfortable with JSON and APIs, do as the developers do and make it easier on your eyes by installing a browser extension:
* For Chrome, JSON Formatter * For Firefox, JSONView
They both do a terrific job of automatically reformatting and highlighting JSON so you can understand what’s going on, and both of them let you easily copy/paste JSON. Give it a shot on the JSON pictured at the top of this page, at the Sunlight Foundation’s description on Facebook’s Graph API.
Either way, the big thing I tried to communicate at Open Data Day this year is that using JSON (and URLs, APIs and most things on the web!) doesn’t require a computer science degree. It’s all just patterns, meant for both humans and computers to understand.
So the next time someone tells you about an API that uses JSON, go ahead and open it in your browser and look it over. Maybe read through the API’s documentation and try to figure out how to get the JSON you want. You’ve always got a CSV converter around if you want to download it as a spreadsheet. You’ve got nothing to lose.