OpenGov Voices: Opening up government reports through teamwork and open data
Last October, while at the [Sunlight Foundation](https://sunlightfoundation.com/), I [kicked off a project](https://github.com/unitedstates/inspectors-general#inspectors-general) to gather the work of every inspector general (IG) in the U.S. government. The project operates by — what else? — web scrapers that reverse engineer every single one of their websites.
Inspector general offices are the independent watchdogs embedded in every federal agency, and they often do fantastic work. You can read [my original blog post](https://sunlightfoundation.com/blog/2014/05/13/why-weve-collected-a-hojillion-inspector-general-reports/) for some more extensive background.
This project has now hit a major milestone, and has gathered the reports of every U.S. federal IG that publishes them.
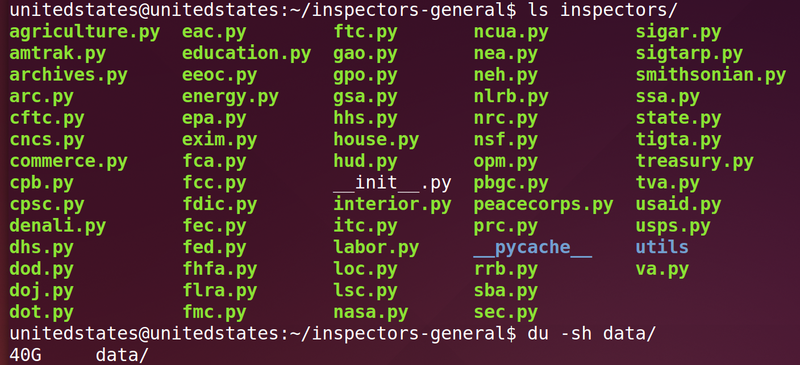
Specifically, we have the work of 65 inspectors general, which adds up to well over 18,000 reports. When sitting next to each other in a folder, they take up 40GB of disk space.
If you’d like to download the entire archive, we’ve [contributed the reports to a collection at the Internet Archive](https://archive.org/details/usinspectorsgeneral). This collection also hosts a [gigantic 34GB zip file](https://archive.org/download/us-inspectors-general.bulk/us-inspectors-general.bulk.zip) of the entire thing. We’ll be regularly updating the collection and the bulk download as a public service.
If you don’t feel like downloading 34GB, every report is [full text searchable in Scout](https://scout.sunlightfoundation.com/search/documents/report?documents[document_type]=ig_report), the Sunlight Foundation’s open government alert service. Sunlight has kept it up to date as new scrapers have been added, so its users have been getting new IG reports delivered to their e-doorsteps for many months now.
## What’s there and what’s missing
The collection includes reports for [any IG listed here](https://www.ignet.gov/content/inspectors-general-directory) that publishes them on their website. We also added the [IG for the House of Representatives](http://house.gov/content/learn/officers_and_organizations/inspector_general.php), because why not?
The gathered reports include:
* Audits of agency programs. * Inspections of agency operations, such as the State Department’s embassies. * Reports to Congress, typically produced twice a year. * Analyses of the agency’s cybersecurity infrastructure. * Peer reviews, where one IG audits the operations of another IG to provide some oversight of the IGs themselves. * Investigations (often criminal investigations), where available. These are often not proactively published. * All sorts of special reports and miscellaneous work.
There are also some things we’re still missing:
* Reports that have only been released through the Freedom of Information Act (FOIA). We generally haven’t tackled FOIA “reading rooms,” nor have we (yet) accepted submissions from nongovernmental actors who received IG reports in response to their FOIA requests. * The work of many intelligence and defense agencies who do not proactively publish their work, such as the [NSA](https://www.nsa.gov/about/oig/) and [CIA](https://www.cia.gov/offices-of-cia/inspector-general). * The contents of many unreleased reports. However, we collected the names and descriptions of many of these reports and flagged them in our data as “unreleased”. These are fertile leads for future FOIA requests.
## What to do next
There’s an awful lot of IG work that can’t be scraped and needs to be requested through the Freedom of Information Act. Many reports already have been, and are sitting in advocates’ inboxes and shared drives. If you’ve got some FOIAed IG reports, please email me and we’ll get them into the collection.
The [Internet Archive](https://archive.org) operates a [magical infinite data upload service](https://archive.org/help/abouts3.txt) where anybody can upload information for preservation and download. We’ve already contributed a [giant bulk zip file of the collection](https://archive.org/details/us-inspectors-general.bulk), as linked above. We’re also working to give every report [its own spot](https://archive.org/details/us-inspectors-general.treasury-2014-OIG-14-023) in the Archive’s collection. This isn’t done yet, but when it is it should make the work more searchable, readable and more reliably preserved.
Full text search is the biggest win, and [Sunlight’s Scout](https://scout.sunlightfoundation.com) provides that, but I think there are a few other ways we could surface IG work to be useful to journalists, activists and curious citizens. For example, the data tracks unreleased reports, which could be used to provide leads for FOIA requests. It’d also be interesting to dig up situations where the agency disagrees with its IG’s recommendations.
## Under the hood: how we collected everything
The IGs do loads of important work, but like so much of our federated government, their work is scattered to the Internet’s winds on 70 different websites. Doing any sort of analysis across IGs — even a simple text search — is completely impossible.
So how do you bring these reports together into something useful? Well, you could either:
* Lobby the IGs to publish standard metadata and feeds for all their reports, or … * _Not_ wait 30 years, and just reverse engineer their websites one by one.
That last one is what you call “scraping,” and it is the last (and often only) resort of data collectors the web over. The U.K. government’s widely admired [Gov.uk hub](https://www.gov.uk/) was famously [built by scraping the rest of the U.K. government](https://gds.blog.gov.uk/2011/05/12/a-brief-overview-of-technology-behind-alpha-gov-uk/). In the U.S., the Sunlight Foundation’s [open data](https://sunlightlabs.github.io/congress/) [services](https://sunlightfoundation.com/api/) are almost entirely comprised of data that has either been scraped, or where the government entity was convinced to release some data so the scraping could stop.
In our case, scraping IG reports means studying an IG’s website, learning its patterns and working out a bit of code to go and extract data from those patterns.
We went in and looked at [IG sites like NASA’s](http://oig.nasa.gov/investigations/reports.html):
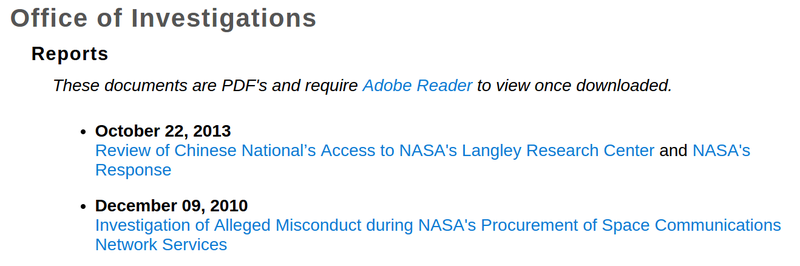
Then we looked under the hood at the underlying source, “HTML.” You can do this in your browser right now by [visiting this link](view-source:http://oig.nasa.gov/investigations/reports.html), or on any page by using your browser’s “View Source” menu option.
The above screenshot looks like this, under the surface:
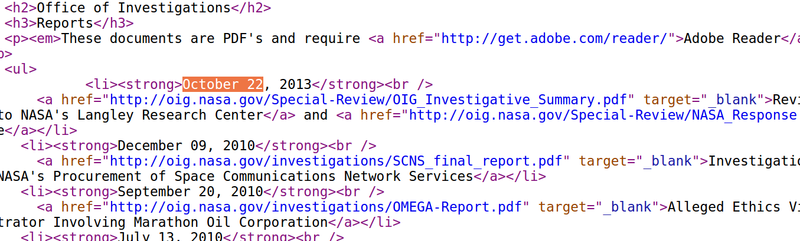
We then wrote a [bit of code](https://github.com/unitedstates/inspectors-general/blob/master/inspectors/nasa.py#L97-L105) in [Python](https://www.python.org) that expects that precise pattern of HTML, and to extract useful data about reports from it. Don’t worry if you don’t understand it, but if you’re curious, this is what actual scraping looks like:

Finally, we wrote some other code that saved all that extracted data as nice, orderly JSON:
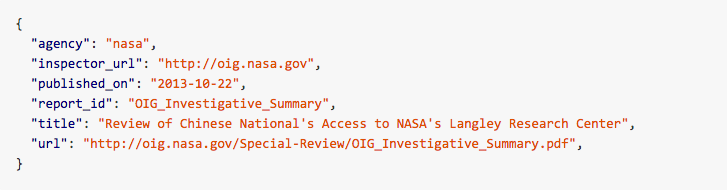
Once the data’s there, you can download the report’s PDF, run it through [basic text extraction tools](https://en.wikipedia.org/wiki/Pdftotext) and after enough of that you’ve got yourself the foundation for a searchable database of reports.
It’s worth mentioning that scraping websites is no substitute for proper open data. As you might guess, in the long run this is not pretty: Website owners update how their website works all the time, without regard to anyone who may have bet on those dates being bolded. When you have to write scrapers, the price you pay is frequent, annoying maintenance, and it gets worse the more you scrape. Our data would be much better, and this process would be much easier, if IGs published this data themselves.
Scraping is fun to do a few times, but at scale it can become very time consuming, as you have to write a new, bespoke scraper for every single website.
## Writing a new scraper for every single website
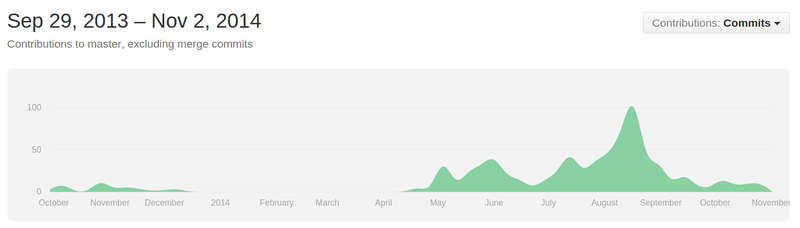
I started by writing two scrapers myself, and by the time I left Sunlight in May, a few volunteers had brought that up to 5. I [excitedly blogged for Sunlight](https://sunlightfoundation.com/blog/2014/05/13/why-weve-collected-a-hojillion-inspector-general-reports/) about the inspector general community, and called for volunteer help to move the project forward.
Over the course of the summer, that call was 100 percent answered.
In particular, I want to thank [Steve Pulec](https://github.com/spulec), who wrote 50 of our scrapers, contributed [over 200 commits](https://github.com/unitedstates/inspectors-general/graphs/contributors) and infused the project with enough energy to make it to the finish line. His code is clear and competent, and he’s done proactive clean up and improvements over the entire system. Steve is the kind of person every open source project dreams of having show up.
I also want to thank [David Cook](https://github.com/divergentdave), who not only chipped in some scrapers, but has gone back and performed _extensive_ data quality work over every single scraper. When you have to resort to web scraping, it’s not always obvious where the gaps and mistakes are, but thanks to David we have much higher confidence that our reports are clean and reliable.
Thanks also to [Lindsay Young](https://twitter.com/not_young), [Travis Briggs](https://twitter.com/audiodude), [Parker Moore](https://twitter.com/parkr) and [Andrew Dai](https://github.com/bunsenmcdubbs), who all chipped in scrapers to get this done!
## Owning public infrastructure
All of this scraping was done as part of [the @unitedstates project](https://github.com/unitedstates), something I [helped start](http://sunlightfoundation.com/blog/2013/08/20/a-modern-approach-to-open-data/), and which over time has become a home for scraping, [data](https://github.com/unitedstates/congress-legislators), [crowdsourcing](http://motherboard.vice.com/read/a-new-open-source-tool-finally-makes-it-easy-to-mass-petition-congress) and even a bit of [open data policy](http://theunitedstates.io/licensing/).
It’s extremely gratifying to see the project keep going, and I think its model — a neutral space where various people and organizations can create basic infrastructure together — is something worth spreading. Because of this, I’m able to continue to develop and drive this IG scraping project, even though I left the organization where I originally started it.
In a common space like [@unitedstates](https://github.com/unitedstates), the infrastructure can and will be developed by anyone with a vested interest, and left still if there’s none. This model may not come so easily to hosted services, but when it comes to public infrastructure — and that’s what government data is — collective ownership is a perfect fit.
Eric Mill currently works for a growing technology team called 18F that builds open, secure technology inside the U.S. federal government. Before that, he spent 5 years with the Sunlight Foundation working on open data infrastructure and policy. The above post describes a personal project and is not part of Eric’s work at 18F. Email him at eric@konklone.com or find him on Twitter at @konklone.
Interested in writing a guest blog for Sunlight? Email us at guestblog@sunlightfoundation.com