The limits and strengths of the US City Open Data Census
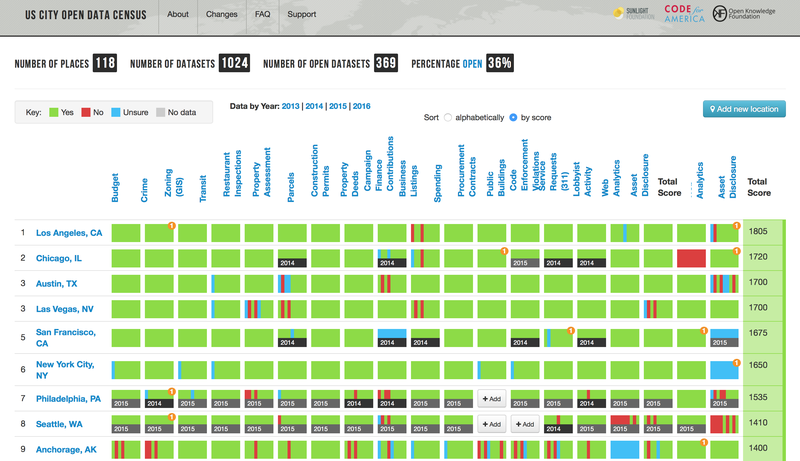
A major challenge in evaluating open data is that there are few quantitative measures of its success. One helpful resource that exists is the US City Open Data Census, a tool that the Sunlight Foundation is now taking a greater role in managing. That said, it’s important to recognize its limitations.
The US City Open Data Census fills several key functions. For open data advocates, it highlights what or where improvements are needed: A city may be keen to digitize bus schedules, but is it releasing the kinds of data — such as on campaign financing or asset disclosures — that help ensure healthy democratic governance? A city may put a wide range of datasets online, but is it making a thorough effort to make data open and easily accessible?
For open data fans in city halls, the census also brings rewards. It validates the hard work of high performers, like Hartford or Austin, and gives officials a chance to show off some city pride. Santa Monica, perhaps confusing us for the federal agency down the street, once touted that it was “officially ranked among the top ten cities … by the U.S. Census Bureau … [for] the City’s open data portal.”
But for all the census’ value, it is not without its limitations, and it’s important to be clear about what those are. They include:
- Missing submissions: Because the census is crowdsourced, overall scores depend on how much information is submitted. Evaluations of the availability of each of the 19 datasets are submitted separately, and cities only get points for data that is available; a dataset whose availability hasn’t yet been evaluated is treated the same as one that is not available. This poses no difficulty for cities with many volunteers happy to analyze local open data, but it can result in lower scores for cities where not all datasets have been evaluated.
- Inaccurate submissions: In addition, not all submissions to the census are accurate. Sunlight does have some safeguards: We have “open data librarians” review all submissions before they appear on the site, we do not allow city employees to review submissions, we publicly display submission dates, and we periodically spot-check submission accuracy. That said, despite our documentation, it is still possible for librarians and individual submitters alike to become confused by standards for “bulk” or “machine-readable” data or to miss finding a dataset that’s already been published.
- Excluded datasets: Even if all submissions are accurate, the 19 datasets currently tracked in the census exclude data on some vital government functions, like health or education.
- Old submissions: Many of the datasets on the census have not had new evaluations submitted for one or two years. Yet a quick look at New York City’s open government timeline for the 2000s and 2010s shows how quickly the open data landscape can change: In 2015 and 2016 alone, New York removed 29 datasets and announced the release of 182 more.
For open data researchers, the fact that the census is crowdsourced complicates any attempt at replicating analyses of the data. With dozens of librarians reviewing data for dozens of cities, the census can change at any moment. In one week in late June and early July, the census received 17 submissions covering Mesa, Ariz.; Seattle; Boise, Idaho; Providence, R.I.; Los Angeles; and Anchorage, Alaska. Just one day can make a difference.
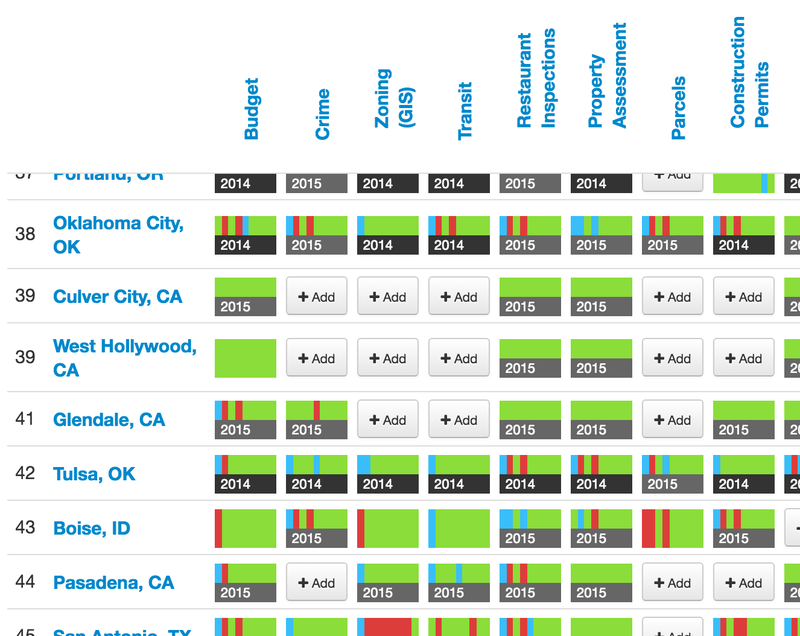
Sunlight is looking at ways to improve the census, but for now, we must be clear about how it should and should not be used. The scores and rankings shouldn’t be considered precise, and the census is not a completely fair way of judging city governments.
Despite these shortcomings, the US City Open Data Census remains “the most comprehensive and straightforward scoring criteria currently available” for municipal-level open data, a report from the University of Southern California observed. Sunlight and its partners have devised a few other ways of measuring open data — such as through surveys to city governments — but the census is unique in providing clear quantitative information for a wide range of datasets in many cities.
It gives an approximation of which cities are doing well with open data and how their practices could be improved, and has immense value as a guide and motivator for cities and advocates hoping to improve open data and government transparency.
Because the census is the best quantitative measure we have of open data success, we hope to address some of its limitations so it can be a more useful component of open data policy analysis. By conducting rigorous analysis, Sunlight hopes to further explore the factors behind the cities’ performance on open data and the policies adopted by the cities. Such analysis will help Sunlight better understand the local governments’ policy choices, further improve Sunlight’s collaboration with them, and in turn improve the cities’ data governance.