Worried about public comments on draft open data policy? Here are the most common sentiments.
Editor’s Note: This is the final post in our three-part series analyzing public feedback on draft open data policies hosted on the Madison platform. The first post discussed which topics are most commonly discussed; the second post discussed who comments most commonly. This post is focused on understanding what topics on open data policies generate positive or negative reactions – and what cities can learn.
Inviting public comments on draft policy is an important way local governments can make sure they are meeting the needs of the people they serve. That type of transparency and accountability can be a daunting proposition, however, especially in the age of angry Internet comments. Are residents going to be supportive or critical? Who will respond? What if they don’t agree with how the policy is written?
Making sure policies are created in partnership with residents can help make the public comment process less intimidating. It can also be helpful to know how residents in other cities have responded to draft open data policy. To give leaders a sense of that, we took a look at the most common sentiments in draft open data policy comments.
A majority of commenters on draft open data policies recommend changes or ask questions regarding different topics such as privacy, transparency, governance, and feedback opportunities. Out of a total of 164 comments on 9 different open data policies, about 32 percent of them expressed enthusiasm about topics, whereas only a little over 5 percent expressed dissatisfaction.
We came up with this analysis by applying machine-based sentiment analysis on comments on online open data policies. Sentiment analysis involves analyzing text to determine emotions. A sentiment analysis tool takes a series of words and assigns a numerical score to it, representing how positive, neutral or negative it is. Then, based on a defined threshold, the series of words is categorized as a positive, neutral or a negative sentiment.
We were excited to see the results an automated sentiment analysis tool would generate if we applied it to online public participation on draft open data policies. Our goal with this work was to identify topics that receive the most positive, neutral or negative reactions.
Most residents gave suggestions for improvements or asked questions
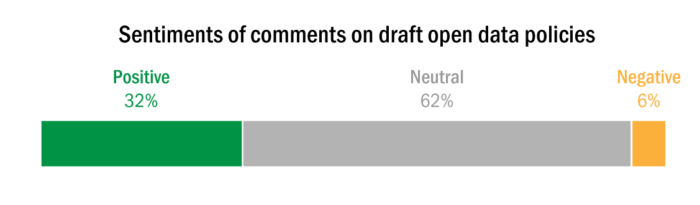 Out of a total of 164 comments, 62 percent of comments were categorized as neutral. Neutral comments were either questions to understand open data policy better or suggestions for improvements to policy.
Out of a total of 164 comments, 62 percent of comments were categorized as neutral. Neutral comments were either questions to understand open data policy better or suggestions for improvements to policy.
In general, people were curious to learn more about how confidential data would be handled, how public records requests would be processed, and whether those requests would be satisfied in a timely manner. They were also interested in the potential for community organizations and academic institutions to host their data on cities open data portals.
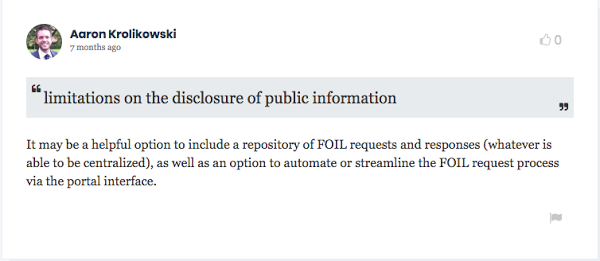
Many residents also made suggestions. Aaron Krolikowski, a researcher, commented on the privacy and security section of Buffalo’s open data policy that:
A sizeable number of users, 32 percent, reacted positively towards open data policies. “I’m so glad that Metro is heading in a more open, transparent direction – and love the idea of Open Data Workshops and public/private partnerships,” said Nashville resident Jennifer Thompson in a comment on their open data policy draft.
Other positive responses were related to policy sections that mentioned that datasets will be made interactive, open data policies will be kept as living documents, and residents will be provided with digital tools to access and use data.
We did identify a few comments that were classified as negative responses. Our survey of those comments found that some of them were suggestions for improvements to policy, however, and did not actually express disapproval of certain policy sections.
One example of this is from Glendale’s open data policy, where one commenter expressed his negative view of the Arizonan city’s existing public participation platform. “This is way past due,” said Gary Deardorff. “The current system is awful and discourages citizen evolvement. Please continue on with this vital upgrade.”
The major limitation of sentiment analysis in this context is that it hasn’t been trained on a dataset of open data policy comments. With more and more relevant data on comments, there is potential for sentiment analysis categories (positive, neutral and negative) to contain comments that are not actually true for these categories.
Nevertheless, this analysis can give cities a better understand of the types of comments on other cities’ draft open data policies. Keeping this information in mind, cities can prepare themselves for common questions before opening draft policies for comment, encourage diverse groups of residents to use open data and comment on draft policies, and finally, listening well to residents who express disapproval of certain topics of open data policies.
By using information on what topics tend to receive most positive or negative reactions, cities can improve upon the ways in which open data policies are written and make sure that the these policies reflect the best interests of residents.