Lessons from Philadelphia’s open data progress

Philadelphia city hall. Photo by Flickr user Scott Baldwin
As open data efforts mature around the country, more places with open data policies are taking the time to reflect on their progress and plan for the future.
Philadelphia, one of the first dozen cities in the country to have an open data policy, is providing an example of what this reflection and planning can look like. The city’s Open Data Team recently released a Strategic Plan and Open Data Census, highlighting lessons from the first two years of its open data program and looking at how to make improvements going forward. Philadelphia’s efforts can help provide lessons to other places looking for ways to be more transparent about the process of opening up data.
The Strategic Plan and Open Data Census are part of a broader revamp of the public open data pipeline for the city. A public-facing pipeline was first launched in March 2013 and maintained on a Trello account that showed lists of published datasets, datasets scheduled for release along with their release dates and datasets that had been suggested for release.
The goal is to build an even more comprehensive foundation for the public display of the city’s data-release progress and plans. One of the first steps in that effort was the completion of the Strategic Plan, which reviews the successes and challenges with open data so far.
Figuring out what data exists — and where it is
One of the problems the assessment revealed is that datasets from the city are spread across websites other than OpenDataPhilly, the portal that is meant to be the primary point of access to the city’s open data. In crafting the Strategic Plan, the Open Data Team found that some datasets were only available on other portals like GitHub, PHLAPI or PASDA. Without proper linking and context, that disparity could mean that people on one website don’t know that the data they’re looking for could be in another location.
This distribution of datasets across various websites presented a challenge with even assessing how many datasets Philadelphia has released so far, but the new Open Data Census captures this information and more. The Census, summarized in the Strategic Plan and available for more in-depth exploration online, revealed that 155 datasets from 29 city agencies or quasi-governmental agencies are currently published in bulk download and/or a public API format. The Census also shows, at least for Philadelphia, that having a policy in place does seem to help the speed of open data release: 111 of the datasets available have been published since the policy was put in place. Just 44 of the 155 datasets were already published before the policy.
Measuring progress
The Census is a snapshot of published datasets and “known unpublished datasets.” The list of “unpublished” datasets was drawn from looking at popular datasets published by other big cities but not yet available online for Philadelphia.
This is where the city decided to take a new approach in evaluating progress. The Open Data Team analyzed the lists of published and unpublished datasets by demand and impact as well as cost and complexity of release. The measure of demand and impact was based on public records requests, public votes on datasets in the city’s original Open Data Pipeline and nominations through the city’s open data portal. The measure of cost and complexity was based on the “technical effort required to prepare each dataset for publishing.”
Using these measures, the Open Data Team found that many of the datasets that rated low on cost and complexity for release have been published. Most of the datasets popular in other big cities but not yet published by Philadelphia rated high on cost and complexity for release. It appears that most of what the city has released to date has been relatively easy-to-release data.
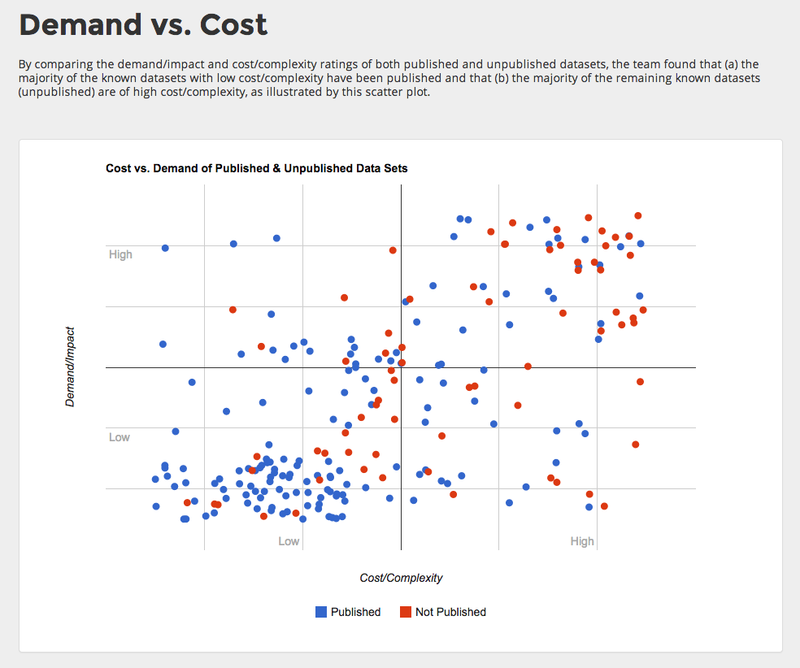
This evaluation points out the need for an approach that deliberately takes more than ease of data-release into account. It’s understandable that easy-to-release data is often what’s first released with new open data efforts as people and technologies adapt to the different way of doing things, but open data initiatives have to mature beyond that. Philadelphia seems ready to work on a meaningful way to achieve this.
The review of progress to date can provide a starting point for determining how to prioritize data release going forward, but there’s still a major challenge: The city doesn’t yet have an inventory of all of its datasets.
The Open Data Team acknowledges the need for a complete data inventory to conduct a thorough and thoughtful prioritization process: Completing such an inventory is listed as one of the goals in the Strategic Plan. The inventory will include “basic information about each dataset such as its title, description, accuracy, and sensitivity” to help departments make prioritization decisions.
This is no simple task. There are other places that are working on or have completed data inventories (with Chicago, New York City and Montgomery County having shared theirs publicly). Not all inventories (planned or completed) are created equal, however. Chicago’s data inventory doesn’t include links to where the datasets can be found online. New York City’s inventory appears to be missing some information and has several other improvements it could make.
Philadelphia will join a small but growing group if it creates a robust and public data inventory. By sharing public lists of published and not-yet published datasets, the city will empower people to find information that is already available online and voice demand for information that is not yet readily available. The idea of more informed prioritization and public engagement around data-release is the driving force behind the federal data inventories mandated by the 2013 executive order, which requires lists of published data, data that is not published but can be, and data that cannot be published along with an explanation of that status. The federal inventory process has encountered its own obstacles, but it will ultimately be an important foundation for a more thoughtful open data initiative. Completing the data inventory will be a great step forward for Philadelphia, too, but it’s what is done with that completed inventory that will matter most.
Crafting a more thoughtful process
Philadelphia will need to create a formal prioritization process that gauges demand from the public for access to specific datasets, demand from inside government, and other factors. The Strategic Plan outlines the multiple approaches the city will take to gauge the demand for and value of releasing certain datasets.
The range of input that will be sought is encouraging: Departmental data coordinators who know specific datasets well will be consulted, an Open Data Advisory Group representing different data users will provide feedback and users of the city’s open data portal will be able to cast votes on datasets as they have in the past. Moving forward with gathering and considering diverse public feedback will be key to helping make sure open data achieves its full potential impact.
Looking ahead
Conducting an evaluation and developing a Strategic Plan like Philadelphia has are part of how places with open data policies are revamping oversight and review of their efforts. The Strategic Plan and Open Data Census are good first steps to crafting a stronger open data program, but how the vision from the assessment is carried out will be the real test of the city’s commitment.
For Philadelphia, the open data pipeline continues a precedent of reviewing and improving set by earlier assessments of the city’s open data efforts and broader transparency initiatives. The first version of Philadelphia’s Open Government Plan was published in October 2012 and updated in 2013, shining a light on the city’s progress with open data and examining areas for improvement.
Since the start of its open data program, Philadelphia has provided a source of inspiration with its efforts. It’s been clear from the beginning that those leading Philadelphia’s open data program value openness throughout the process of making data open, and they value diverse community input in that process.
One of the most encouraging themes of the Strategic Plan is that it emphasizes the need for taking open data “from a special initiative in which departments participate to the way of doing business as a government in Philadelphia.” This is the direction in which all places with open data policies will need to move for continued success. Open data cannot just be a movement — it needs to become the norm. Philadelphia should seize the opportunity to embody that spirit and show — openly — just how that goal can be achieved.